by Geetika Palta, Mithila A. Sarah and Susan Thomas.
Measuring the impact of financial inclusion
Households use financial instruments and financial markets to achieve their lifetime objectives. These include being able to smooth consumption over time, being able to withstand shocks, and pursue entrepreneurial opportunities to gain income mobility. Financial inclusion refers to such access to finance for a larger subset of the population (e.g. Rao, 2018). Financial policy makers have pursued financial inclusion for many decades. In recent years, the rise of ESG investors has bolstered private sector interest in financial inclusion.
For policy makers, for financial firms, and for ESG investors, there is thus an interest in the measurement of financial inclusion (Sarma M., 2016; UNEP FI, 2021). The field of measurement of financial inclusion is under-developed. While there is high interest in building such measures (RBI, 2020; El-Zoghbi, 2019), there are debates about methods and no single measure has been widely accepted (Nguyen, 2021).
Financial inclusion should improve the life of the household through smoothing consumption, withstanding shocks to income and helping the household achieve income mobility to a higher sustained level of consumption. For example, learnings from a financial literacy program in the Philippines show how Filipino households obtained income mobility (Monsura, 2020). These households learned how to take advantage of the economic opportunities through savings, investment, insurance, and entrepreneurship. Access to formal financial services and the ability to use them enables the households build wealth and generally live a financially secure life.
An inputs-outputs-outcomes framework
The inputs-outputs-outcomes framework is valuable in many aspects of policy thinking. As an example, in a domain like education, the input is school buildings, the output is children spending hours in school, and the outcome is the change in their knowledge (Banerji et al., 2013).
This approach is valuable in the field of financial inclusion also. The input is household participation in formal finance (such as account opening or purchasing health insurance); the output is the intensity of transactions (how frequently the account is used or whether the insurance premium is paid on a regular basis) and the outcome is the impact on economic well-being.
This perspective upon financial inclusion guides measurement methods for financial inclusion. Measurement of financial inclusion needs to measure inputs (presence of various financial products and services in the household portfolio), outputs (the use of financial products in achieving household objectives) and outcomes (stability of consumption and income mobility).
Done right, such measures can facilitate a deeper understanding of the impact of financial inclusion on the economic well-being of a household. These measures can help identify gaps in financial inclusion, both in terms of missing products in the household financial portfolios, as well as excluded household groups. For ESG investors, these measures can play a role in their principal-agent problems with portfolio companies.
In this article, we propose and implement a simple financial inclusion input measure, which is the household participation in the formal financial sector, calculated using the sample of households in the CMIE CPHS data. With this, we show some important facts about financial inclusion inputs in India.
Difficulties of conventional measures
In the early stages of measuring financial inclusion, crude proxies were used for measurement at the level of the economy, such as M2 (cash, demand and time deposits) as a percentage of GDP. Later, more systematic data collection about household holdings of financial assets began (Beck, 2016). Most of these measures were typically country-level aggregates organised around financial service provider (FSP) or one class of financial product (RBI, 2017). While aggregates at the country level are useful, they can mix up usage by some households and absence by others. What would be most useful is to construct financial inclusion measures at the level of a household, pulling together a full picture of the financial activities of the household (Campbell, 2006).
More often than not, there has been a bank-orientation in these measures with focus on number of bank accounts, bank branches, number of ATMs and amount of bank deposits. But there is much more to financial inclusion than banking. Gupta and Sharma (2021) point out that measuring ownership of bank accounts alone tends to overestimate and present an incomplete picture of financial inclusion as it neglects access to and use of the full range of financial products. Over time, the focus of financial inclusion has shifted towards a larger set of financial assets and usage of digital payment systems (RBI, 2020).
The construction of financial inclusion measures at the level of a household pre-require a capture of such information from households themselves. There are a few rare instances where countries have administrative data from which asset portfolio by households can be constructed (Calvet et al., 2007; Andersen et al., 2020). Most countries do not have such data on household portfolio of financial instruments (Badarinza et al., 2016; IFC, 2011). Over the last decade or so, household surveys have emerged that record household portfolio of financial instruments. Most of these have been one time surveys or surveys done at low frequencies. For example, in India, the NSSO AIDIS captures household level participation in financial systems once in 10 years.
Constructing a household `Financial Participation Score' (FPS) using CPHS
An important household survey that is conducted thrice a year over a sample of 170,000 households is the Consumer Pyramids Household Survey (CPHS), by the Centre for Monitoring Indian Economy. Given India's high economic growth rate and the rapid pace of change in the last few decades in finance, this survey makes possible new insights into financial inclusion of Indian households in a timely and geographically dis-aggregated manner.
The CPHS has member-wise characteristics and household characteristics such as income and expenditure of households, what assets they own and whether they have borrowings. Household data on financial assets owned comes from the ''People of India database'' and the ``Household Aspirational India database'' in CPHS. In the former, households are asked questions on ownership (Yes/No) of four different financial instruments, while the latter measures outstanding investment (Yes/No) in six financial instruments. We use the following variables to measure the financial participation of a household:
- Household ownership of at least one bank account (Bank), at least one health insurance (HI), at least one life insurance (LI), at least one employee provident fund account (EPF).
This captures four components of financial inclusion.
- Outstanding investment at a household level in fixed deposit (FD), Kisan Vikas Patra (KVP), National Savings Certificate (NSC), Post Office Savings account (POS), Mutual Funds (MF) and Listed Shares (LS).
This captures six components of financial inclusion.
Put together, there is data about 10 financial instruments -- all zero/one values -- that households hold at a point in time. We define a Financial Participation Score as sum of the values divided by 10. This gives the household an FPS that runs from 0 to 1. For example, an FPS value of 0.3 indicates that the household owns three of the ten financial instruments.
The CPHS data on household holding of the 10 financial instruments is captured three times a year in three ``waves'' where each wave is completed over four months and surveys about 170,000 households. In each year, Wave 1 consists of January, February, March, April 2021; Wave 2 has May, June, July, August and Wave 3 has September, October, November and December. Households are generally measured in a consistent month slot within each wave thus generating a regular cadence in the time-series for each household.
All the 10 instruments used in this calculation involve households carrying consumption from the present into the future. In this article, we do not include debt-related variables in calculating financial participation, even though borrowing is one form of finance used by many households. For one, debt is multi-dimensional. It can be from different sources (formal vs. informal), have different maturities, be driven by different purposes. While all debt involves carrying consumption from the future to the present, the impact of debt on the future well-being of the household can vary. Some debt is for short-term consumption smoothing, possibly at the cost of lower consumption in the future. Other types of debt may lead to higher income in the future if they are used to build enterprise. Given this multi-faceted nature of household debt, it's inclusion is left for downstream research.
We construct an unbalanced panel data-set of household FPS at the wave level, for 2014-2021, with three waves per year. The number of households observed varies from 76,386 (during the lock-down in 2020) to 1,49,160 (2018). The CPHS is a stratified random sample. However, for the purpose of this first exploration of basic facts, we have reported unweighted summary statistics.
Some basic facts about the FPS
The household FPS is calculated for each wave. The annual FPS of a household is calculated as the maximum value of FPS observed for the household across all the waves for which it was observed. The summary statistics of annual household FPS values are presented in Table 1 for each year of the panel data-set.
Table 1: Summary statistics of household FPS, from 2014 to 2021
|
2014 |
2015 |
2016 |
2017 |
2018 |
2019 |
2020 |
2021 |
| Min |
0.0 |
0.0 |
0.0 |
0.0 |
0.0 |
0.0 |
0.0 |
0.0 |
| 25th |
0.1 |
0.2 |
0.2 |
0.2 |
0.2 |
0.2 |
0.2 |
0.1 |
| 50th |
0.2 |
0.3 |
0.3 |
0.3 |
0.3 |
0.3 |
0.3 |
0.2 |
| 75th |
0.3 |
0.3 |
0.4 |
0.3 |
0.4 |
0.4 |
0.4 |
0.3 |
| Max |
0.9 |
0.9 |
1.0 |
1.0 |
1.0 |
1.0 |
1.0 |
0.9 |
For most of the years, 50 percent of the households hold 3 or fewer instruments. This holds steady for the 6 year period, for most part. There continue to be households with FPS of 0. This implies that there continue to be households that do not even have bank accounts in this sample.
There have been minor shifts in financial participation of the households in this period. The COVID-19 pandemic lock down of April to June 2020 appears to have an adverse impact. By 2021, the median household has dropped from holding 3 instruments to 2. This is a consistent drop -- the 25th percentile household have dropped from 2 to 1 instrument, and the 75th percentile household has gone down from 4 to 3.
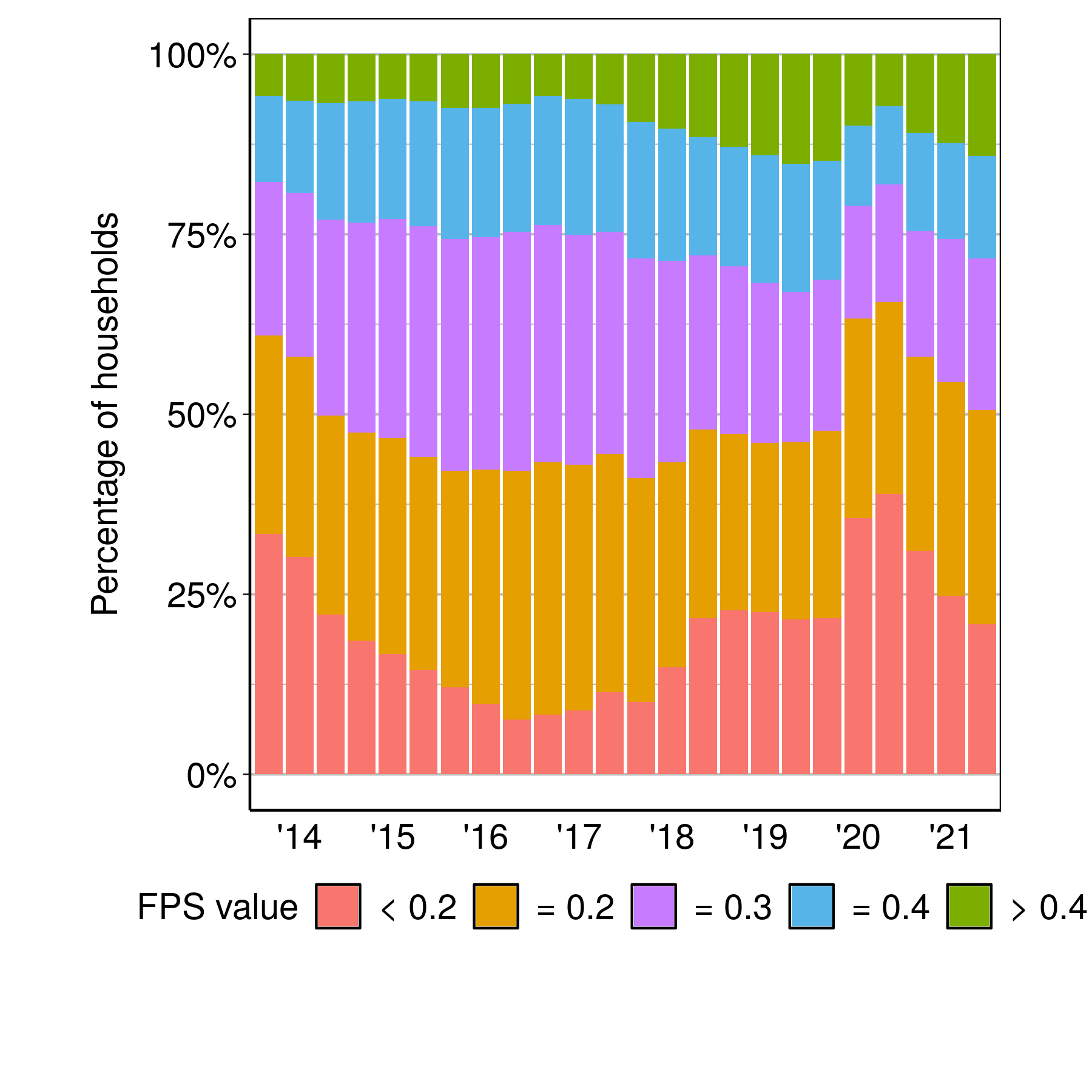
We next examine the cross-sectional variation in household participation. For this, we categorise all households into five groups: those with (1) FPS less than 0.2, (2) equal to 0.2, (3) equal to 0.3, (4) equal to 0.4, and (5) greater than 0.4. Figure 1 shows the fraction of households in each of these FPS categories, in each wave.
Figure 1: Distribution of households by categories of FPS
Figure 1 shows that there was an increase in household financial participation in the early part of this sample, from 2014 up until the end of 2017. (The areas under the sum of FPS categories >= 2 have dropped in this period.) In 2018 and 2019, there was no change in the fraction of households across the defined categories. The changes of 2014-2016 appear to reverse from the second half of 2020 onwards. By 2021, the fraction of households with FPS >= 0.3 is nearly the same as the values seen in 2019.
What was happening at the level of the individual instruments?
In Figure 2, we go below the aggregate FPS into portfolio of individual instruments, including bank accounts, fixed deposits, pensions, post office savings, health insurance, life insurance, mutual funds and listed shares. (We do not include the household holdings of KVP and NSC because these fractions were very small compared to the selected eight instruments in the figure.)
Figure 2: Distribution of households portfolio of individual financial instruments by wave (log scale)
Health insurance had the highest growth (10 percent of households holding to 40 percent of households holding in the sample in a wave). At the same time, life insurance saw a drop (from 60 percent of households holding to 40 percent of households in the sample holding this in a wave). Post office savings saw an increase (from 8.5 percent of household holding to nearly 20 percent of households holding) while pensions saw a decrease (from 25 percent of household holding to around 18 percent). While the numerical values are small, there was strong growth in mutual funds and listed shares.
How different is financial inclusion for rural vs. urban households?
How does the financial participation of urban households compare to rural households? In the following Figure 3, we examine the distribution of rural and urban households in the four FPS categories presented in Figure 1.
Figure 3: Distribution of rural and urban households by categories of FPS
The figures show that the distribution of rural households tend to have lower financial inclusion compared to the urban households. More interesting is the difference in the evolution of financial inclusion between these two groups. Both rural and urban households saw increasing financial participation in 2015 and 2016 compared to 2014. However, financial participation of rural households stalled at the end of 2016, while urban households contend to grow their financial participation. Financial participation for both rural and urban households worsened first in 2018, and then more sharply in 2020, at the time of the pandemic.
We also examine what are the differences in financial instruments holdings behind the variation that we see in the financial participation of rural and urban households. From Figure 4, we can see that rural and urban households are similar in their holding of bank accounts, fixed deposits and post office savings. But they are distinctly different in their holding of EPF, mutual funds and listed shares, where there is a higher fraction of urban households holding these instruments compared to rural households.
Figure 4: Distribution of rural and urban households' portfolio of individual financial instruments
Figure 4 also shows us that the growth in fraction of households holding individual instruments vary between rural and urban households. There was a higher growth in fraction of rural households holding health insurance (from 5 to 40 percent), while for urban households this was lower (from 10 percent to 40 percent). There was a drop in the fraction of rural households holding life insurance compared to no change in the fraction of urban households holding these.
This tells us two pertinent aspects of the growth of financial participation across rural and urban households: first, financial participation by rural households appear more vulnerable to external shocks -- such as demonetisation, the ILFS-NBFC crisis and the pandemic -- than urban households. Second, there is some variation in what types of instruments rural households tend to hold compared with urban households.
In the CPHS sampling strategy, there is a roughly two-times over-weighting of urban locations. The simple summary statistics shown in this article (i.e. unweighted estimates) are problematic; for more precise estimates all summary statistics require appropriate weighting. It is hence particularly useful to see the urban and rural values separately, as has been done here.
Conclusions
It is widely believed that improvements in financial inclusion will translate into reductions of consumption volatility and increased odds of improved lives. Greater research is required on measuring the strength of these relationships. In the standard recipe of phenomenological research, we require measurement of a phenomenon, and then it becomes possible to analyse the causes and consequences.
An important missing link in the field of financial inclusion are tools for measurement. In this article, we have shown a first and simplest measure, an input measure, about use of the formal financial system by households. This measure can be computed at the household level, three times a year, in the CMIE CPHS survey database.
In the summary statistics shown here, there have been only small changes in the overall average FPS over the years under examination. The median value for urban households was 0.3 and the median value for rural households was 0.2. We see a visible decline of the FPS in the lockdowns of 2020, and in the post-pandemic economic recovery, the FPS has come back to near pre-pandemic values. These results suggest numerous questions about causes and consequences, which need to be explored in downstream research.
This ability to observe the FPS at the level of a household enables new kinds of academic research, new kinds of feedback loops for policy makers, and definitions and measurement to help ESG investors overcome principal-agent problems between the investor and the fund, and the fund and the portfolio company.
References:
Andersen, S., Campbell, J. Y., Nielsen, K. M., & Ramadorai, T. (2020). Sources of inaction in household finance: Evidence from the Danish mortgage market, American Economic Review, 110(10), 3184-3230.
Badarinza, C., Campbell, J. Y., & Ramadorai, T. (2016). International comparative household finance, Annual Review of Economics, 8, 111-144.
Banerji, R., Bhattacharjea, S., & Wadhwa, W. (2013). The annual status of education report (ASER), Research in Comparative and International Education, 8(3), 387-396.
Beck, T. (2016). Financial Inclusion–Measuring progress and progress in measuring.
Calvet, L. E., Campbell, J. Y., & Sodini, P. (2007). Down or out: Assessing the welfare costs of household investment mistakes, Journal of Political Economy, 115(5), 707-747.
Campbell, J. Y. (2006). Household finance, The Journal of Finance, 61(4), 1553-1604.
El-Zoghbi, M. (2019). Toward a New Impact Narrative for Financial Inclusion, CGAP, 2019.
Gupta, S., & Sharma, M. (2021). A Demand-Side Approach to Measuring Financial Inclusion: Going Beyond Bank Account Ownership, Dvara Research Working Paper Series No. WP-2021-05.
Monsura, M. P. (2020). The importance of financial literacy: Household's income mobility measurement and decomposition approach., The Journal of Asian Finance, Economics and Business, 7(12), 647-655.
Nguyen, T. T. H. (2021). Measuring financial inclusion: a composite FI index for the developing countries , Journal of Economics and Development, Volume 23, Number 1, pp. 77-99, 2021.
Nilekani N (2019). Report of the High Level Committee on Deepening of Digital Payments, Reserve Bank of India.
Rao, K. S. (2018). Financial inclusion in India: Progress and prospects , The Ideas for India blog, 2018.
RBI (2017). Report of the Household Finance Committee on Indian Household Finance, 24 August 2017.
RBI (2020). National Strategy for Financial Inclusion 2019-2024 .
Sarma, M. (2008). Index of financial inclusion Working paper No. 215, ICRIER, New Delhi.
Sarma, M. (2016), Measuring financial inclusion using multidimensional data, World Economics, 1 Ivory Swuare, Plantation Wharf, London, UK, SW11 3UE, vol. 17(1), pages 15-40, January 2016.
International Finance Corporation (IFC) (2011). Financial inclusion data: assessing the landscape and country-level target approaches. The World Bank, 2011.
United Nations Environment Program Finance Initiative (UN EPFI) (2021). 28 Banks collectively accelerate action on universal financial inclusion and health, 2 December 2021
Geetika Palta, Mithila Sarah and Susan Thomas are researchers at the XKDR Forum. We thank Ajay Shah and three anonymous referees for valuable comments and suggestions.